

After a few years of learning and using R to perform cognitive neuroscience and psychology research, I joined Convo in March 2018 as their Data Scientist. I report to their Director of Engineering, which places me squarely on the same team as software, app, and internal systems engineers.
It’s been a steep — but very fun — learning curve as I learn how to work in a software engineering environment, having had zero prior experience with software development or any of that app coding stuff. Soon after joining Convo, my work made a hard turn into the realm of data engineering when I got my first major project: “set up a data warehouse.”
I never heard of a data warehouse before. So I asked my CTO. “Data that all go in one place, and that enables us to identify business opportunities and helps teams easily make data-driven decisions,” she explained.
Sure, but what’s the difference between that and a regular MySQL database? I wondered.
Having a PhD means I should be good at research, right? So I put those skills to use and dived straight into the brave new world of data stacks and data engineering. It’s indeed a “brave new world” because a whole host of data engineering theory, SaaS vendors, community Slacks — really, an entire ecosystem — have sprung out of seemingly nowhere to address data needs that didn’t exist a decade ago.
The good news is this new ecosystem is full of very helpful, engaging people who want to make easier the difficult jobs of (1) getting data from one place to another place and (2) turning raw data into usable data. The bad news is, if you’re not sure where to start (e.g., “what’s ETL?”) or even what keywords to put in Google, it’s easy to get off-track. The ecosystem has changed very fast, so my research often sent me towards vendors selling costly, legacy-ish data management systems that appeared to be built on top of outdated data assumptions. After some time and countless Slack chats, my understanding slowly crystallized into, “I’m building a data stack.”
So -- what's a data stack?
A data stack makes data edible. A data stack is like a kitchen for data. Think of how you bake a cake:
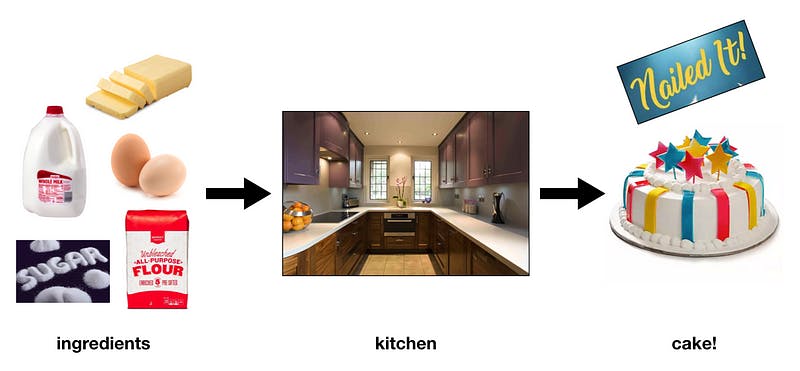
See how the ingredients become a cake after going ‘round a kitchen? Most cake ingredients aren’t edible by themselves (they contain nutrients, yes, but you wouldn’t have the most fun time munching on flour or butter sticks). But after spending some time in the kitchen with the proper tools: a mixing bowl, an oven, a kitchen timer, a cake pan, spoons and spatulas, a chef who can follow instructions, these formerly-unedible ingredients turn into a lovely cake anyone’d be happy to nosh on.
And that’s the key thing. Bits of data sitting here and there by themselves aren’t so edible. But after journeying through a data stack, the bits of data have turned into useful fact and dimension tables with clear field names and types, easily digestible by different departments in a company.
How unedible data becomes edible data.
Yep, nailed it. What’s inside that data stack? It’s not just a data warehouse! Data stacks are composed of tools that perform four basic functions:
Loading: move data from one place to another. Vendors include Alooma, Fivetran, Stitch.
Warehousing: store it all in one place, usually on the cloud. Vendors include BigQuery, Redshift, Snowflake.
Transforming: turn it into edible data. Vendors include dbt, ETLeap, XPlenty.
Analysis & Business Intelligence: serve it up to teams. Vendors (and there are a lot of them!) include Chartio, Cluvio, Looker, Metabase, Mode, Periscope.
Any tech company who cares about data should have a data stack that does all four functions. The data stack I’ve built at Convo ticks off these requirements. All the components work together like a dream, and teams are starting to gobble up the data left and right.
My speedy education in this realm has been greatly aided by the awesome folks at Fishtown Analytics (creators of dbt and Sinter) and the very active dbt Slack community they moderate. If you’re a new data engineer or a data scientist who, like me, does a lot of engineering-y stuff, this is the place to hang out. Also helpful are Stephen Levin’s resources, as well as the Future-Proofing your Analytics Stack video from Mode. In particular, that video compares all-in-one vs. modular data stacks, which is an important question to consider when designing your data stack.
Happy data stack building!
P.S. Back to my question above: why not just use a MySQL database for a data warehouse? Because the amount of data you’re importing from all these sources probably is going to be massive, and it’ll consume a lot of processing time to transform all that data. Flexible cloud-based data warehouses are the way to go, and virtually all data loading tools support those as data destinations, and likewise with data reporting tools using those as data sources.
P.P.S. I’ve also seen people call data stacks “BI stacks” and “analytics stacks.” FYI.