

I’ve been excited about SQLMesh since it was released to the public a few weeks ago. It’s fantastic to see innovation in the data transformation space and teams boldly testing out novel approaches to managing ever-ballooning data assets in cloud data warehouses. 🚀
Here, I’ll go over how SQLMesh approaches production vs. development schemas differently than how it’s done using dbt (which I’ve used since 2018 and don’t plan to stop anytime soon!).
📝 The SQLMesh team also published a blog on the same topic within minutes of my posting this article! For a more in-depth and technical discussion, check out Iaroslav Ziegerman’s Virtual Data Environments article.
Virtual data environments 🏪
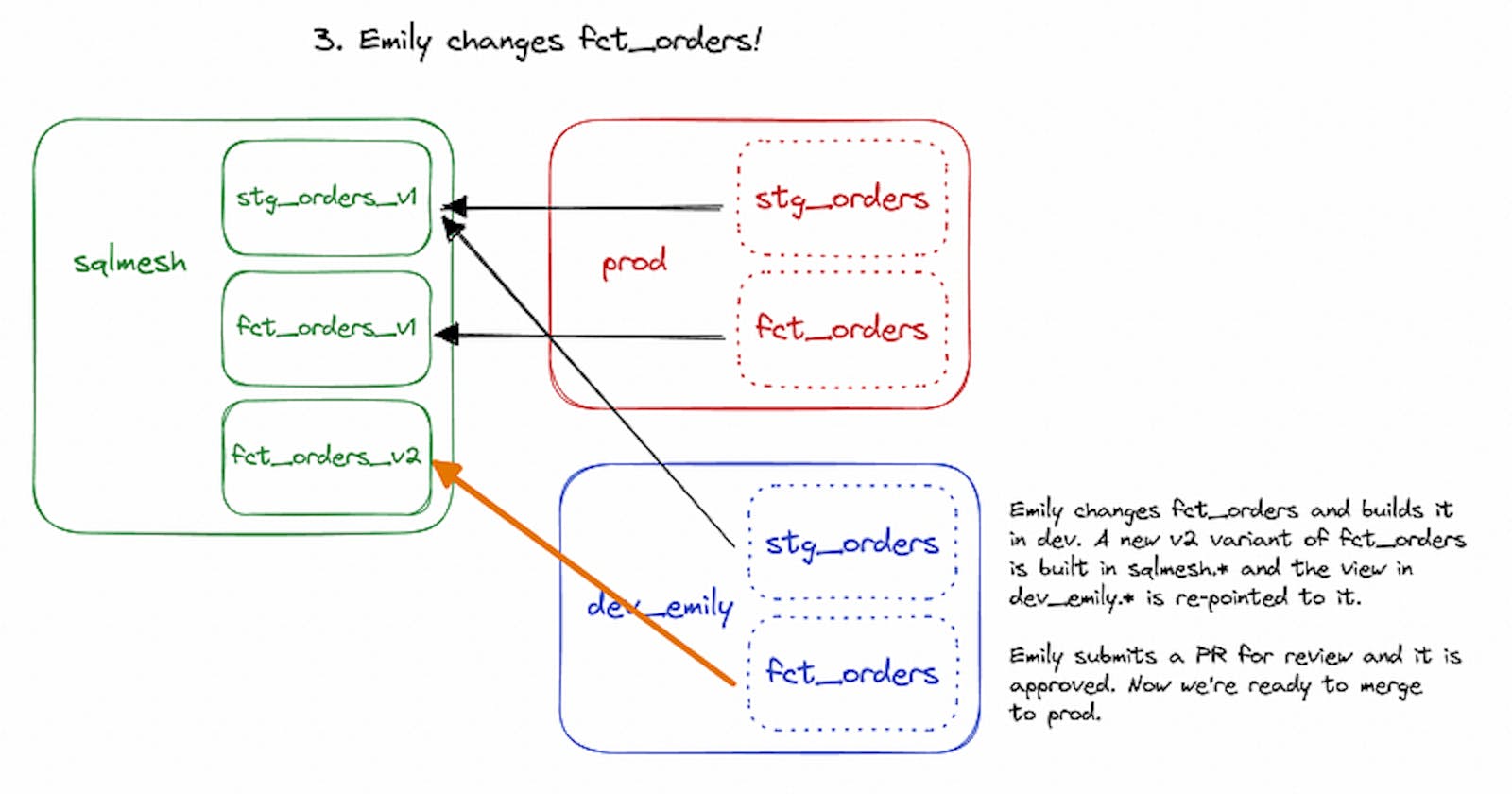
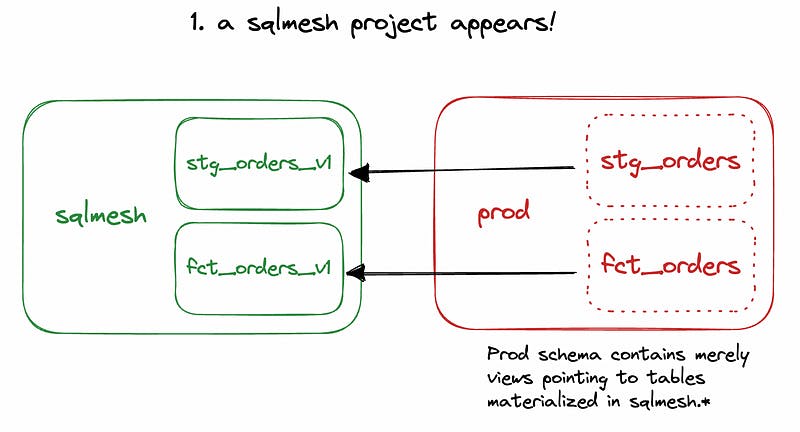
A core concept in SQLMesh is the idea of virtual data environments which are a set of views in a schema that point at materialized tables stored in a separate schema (I’ll call this the “storage schema”). Views are essentially freebies so you can have as many virtual data environments as you need, since they’re all just select * views pointing to materialized tables in the storage schema. The production schema is a virtual data environment, and your and your team members’ development schemas are also virtual data environments.
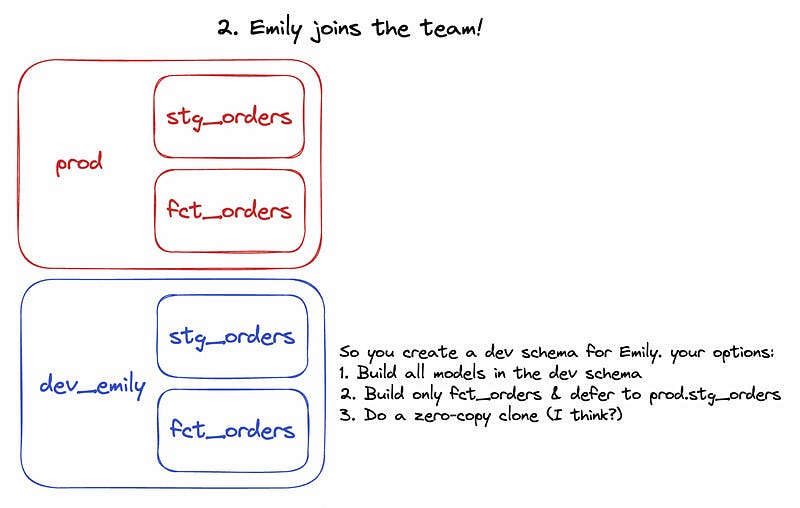
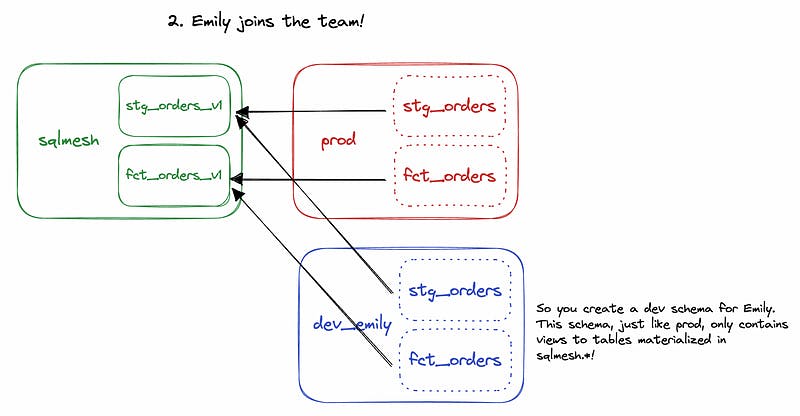
Virtual data environments make it very simple to think about development environments. When you join a data team using SQLMesh and start developing, SQLMesh will basically clone the production schema (remember, which are all just views) and create a development (dev) schema for you, containing that same list of views pointing to materialized tables in the storage schema. When you’re writing new models, these new models reference views in your dev schema, which in turn reference production data in the storage schema. This is an improvement over needing to materialize all upstream tables in your dev schema or dealing with deferrals to previous states in order to access production data. Only net-new tables need to be materialized, and are materialized in the storage schema where all other materialized tables go.
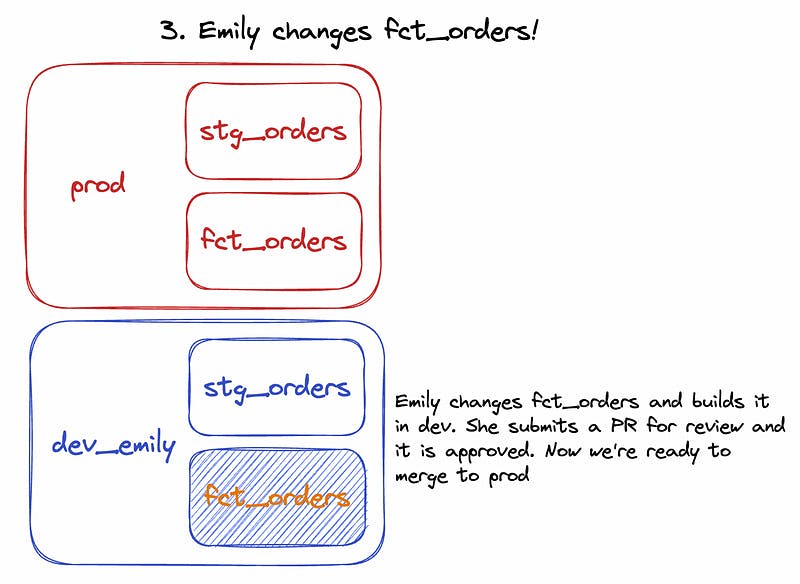
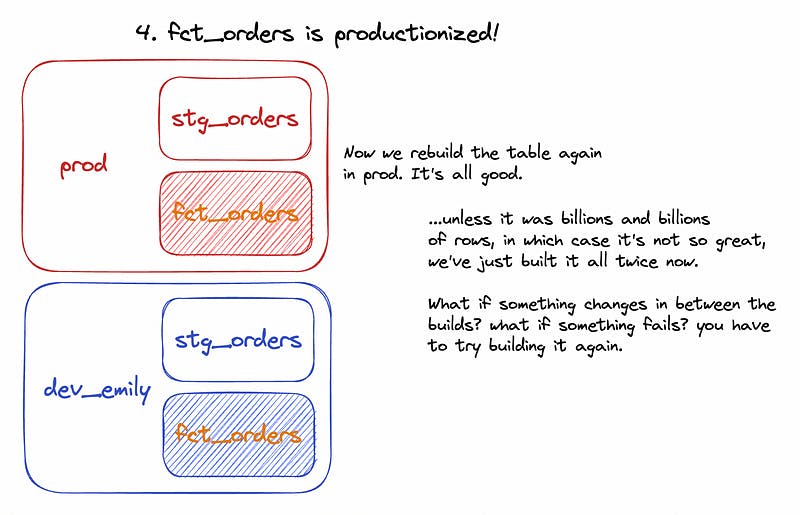
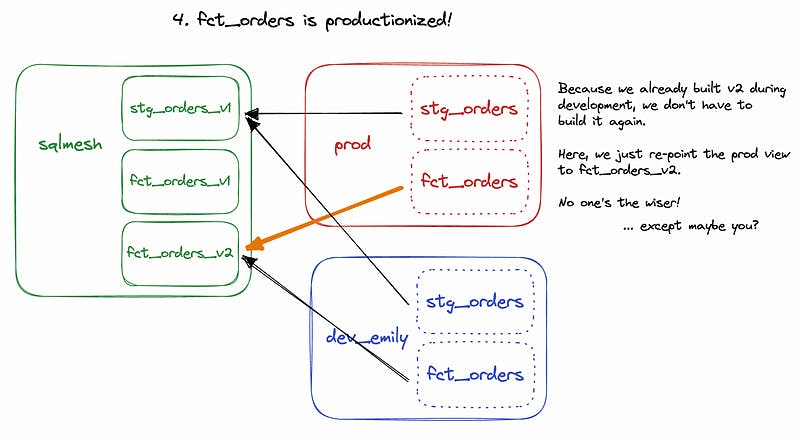
Updating an existing model? As you’re editing, each iteration is materialized in the storage schema. When you release a new version to production, SQLMesh simply updates the view’s definition in the production schema to point to the latest iteration in the storage schema. Previous iterations are still available in the storage schema until dropped by a scheduled cleanup job (so rollbacks are essentially free!).
If none of that made sense, that’s fine, because I illustrated it here too! First, I show how development typically works in dbt, and then contrast that with SQLMesh’s approach.
dbt’s approach
SQLMesh’s approach

In Closing: Time & Money
What does all this mean? Fewer model rebuilds and full-refreshes. As dbt-based data transformation pipelines increasingly handle hundreds of models containing billions of rows, two things start happening: (1) materializations and full refreshes grow longer and more computationally expensive, and (2) teams start having a harder time deferring to previous states within development environments (manifest.yml, ugh). ⏲️ and 💸
dbt Labs is also working on challenges with large-scale & enterprise-scale data transformation projects (i.e., multi-project deployments are coming). What’s really exciting here is seeing all these new ideas and solutions in the data transformation space which I think only gives us analytics engineers (and data engineers and data analysts and all the other jobs to be done) ✨more tools to do the job. ✨
There’s plenty more cool features in SQLMesh that I haven’t seen in other tools, and I hope to write about those later.